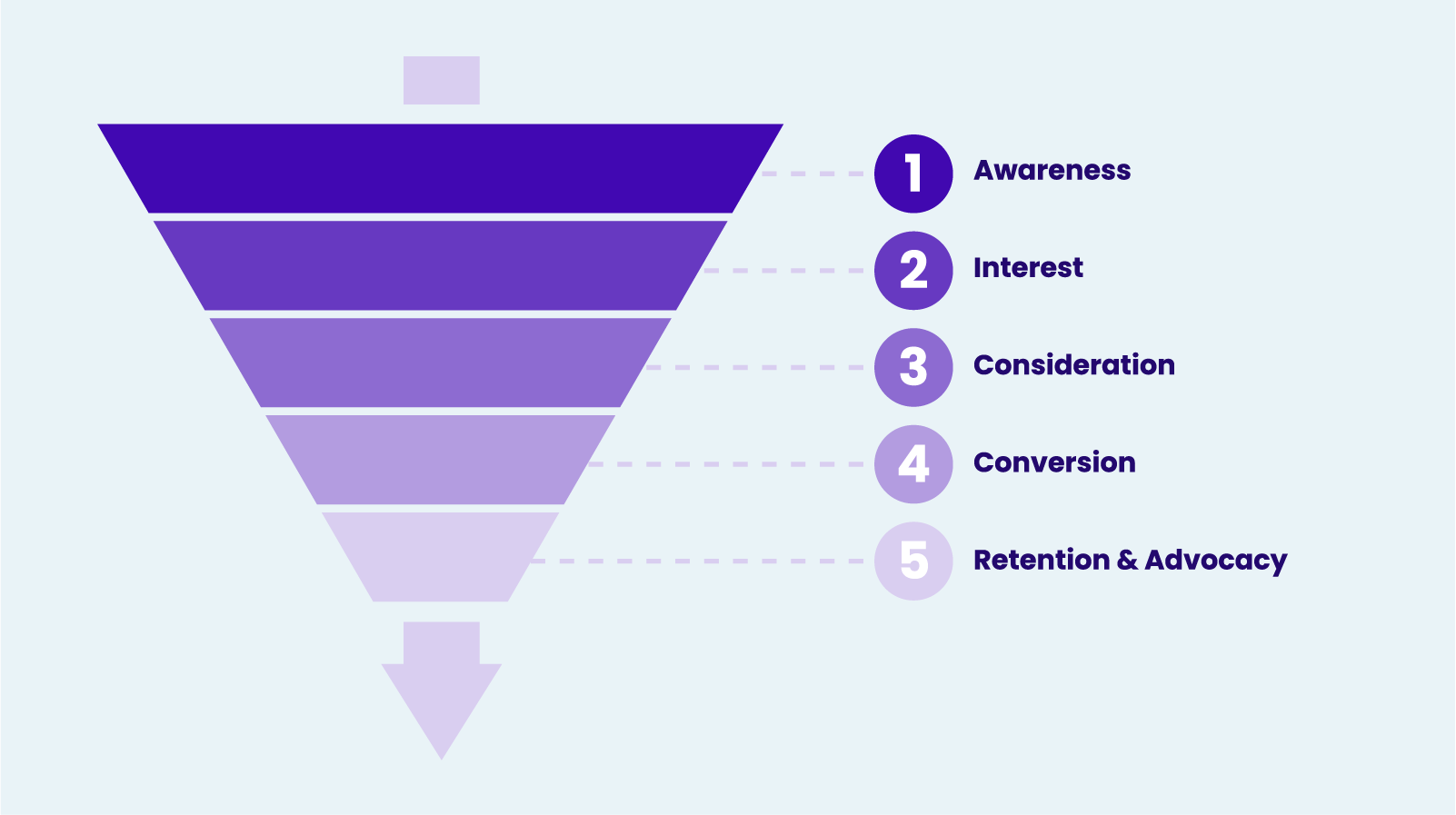
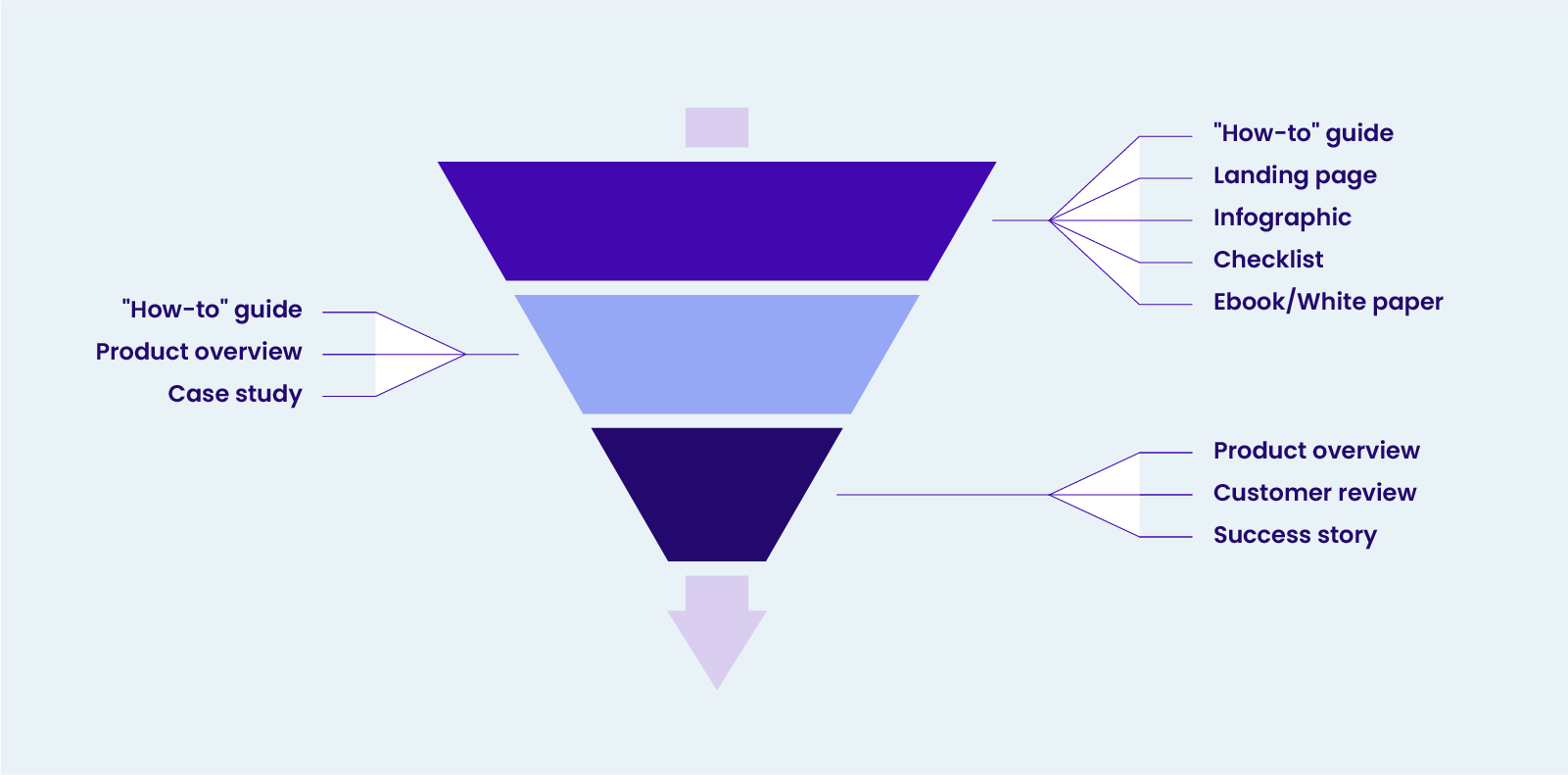
Search engine optimization (SEO) and search engine marketing (SEM) are different forms of digital marketing that require distinct skill sets and approaches, but one is not complete without the other.
Utilized correctly, SEO and SEM complement each other, allowing a marketing team to balance short-term and long-term gains to achieve their goals more effectively than they could using only one or the other.
Read on to learn how both SEO and SEM work, and why they serve as complementary cornerstones in an effective digital marketing strategy.
What’s the difference between SEO and SEM strategy?
Search engine optimization (SEO)
Search engine optimization is the practice of continuously updating web pages to ensure they rank as well as possible for search engine result pages (SERPS) related to the keywords they’re targeting.
SEO refers to all activities focused on enhancing a page’s organic SERP ranking. Unlike SEM, SEO practices don’t involve explicitly paying search engines to appear in SERPs. Instead, this discipline is about creating and optimizing high-quality content that aligns with user intent to rank near the top of searches for important keywords and queries.
All on-page website optimizations you implement to improve a page’s SERP ranking could be considered part of your SEO strategy. These include keyword research and implementation, content optimization, link building, user experience improvement, and more.
Search engine marketing (SEM)
Search engine marketing is sometimes used as an all-encompassing term for search-related marketing activities (including SEO), but often refers specifically to paid search engine advertising. Where SEO aims to rank on SERPs organically by providing best-answer content, SEM initiatives involve using paid advertisements to increase SERP visibility for a predetermined set of highly valuable keywords. SEM ads can appear in the “sponsored” section at the top or bottom of a SERP, or in an additional designated space to the side of the results.
Though SEM involves direct paid advertising, it still requires considerable strategic planning and maintenance. Most search engines use a bid-based pay per click (PPC) model to determine which paid advertisements appear per SERP. These auctions occur whenever a SERP is called up by a user; winners are determined not only by the amount bid by each advertiser, but also by the quality, relevance, historical click-through rate, and more.
SEO and SEM differences in practice
The primary difference is that SEM refers to appearing in SERPs by paying to place advertisements in them, while SEO refers to everything you do to appear in SERPs without explicitly paying search engines to be there.
This distinction means SEO and SEM are typically used for two different but interrelated purposes. SEO is considered the long-term play for rankings. By steadily building authority and following SEO best practices, sites can improve their SERP rankings and, therefore, their brand’s visibility and share of mind.
Meanwhile, SEM is considered a short-term play for rankings and visibility. Though paying to appear in SERPs perpetually is not cost-efficient compared to SEO, SEM does offer brands the ability to appear at the top of SERPs for valuable keywords almost immediately, driving more surefire conversions. This allows organizations to devote extra resources to promoting tentpole marketing initiatives like special deals, announcements, or branding pushes.
How SEO and SEM strategies support each other
Despite their differences, brands tend to get the most out of both SEO and SEM by using them in tandem. The two approaches to search marketing naturally complement and enhance each other in several ways.
SEM visibility now, SEO authority always
SEO takes time, but it’s ultimately the best way to drive sustained, relevant, cost-efficient traffic to your website. SEM produces immediate visibility, but relying on it for too long will lead to high CPAs and diminishing returns. A strategy that uses both, however, can get the best of both worlds.
By targeting high-value, conversion-focused keywords with SEM, you can quickly generate attention and engagement in a short period. While driving these quick results, you can then focus on organically optimizing your landing page (and the rest of your supporting content), benefitting from the added traffic and first-party data it produces.
Good SEO leads to lower SEM costs
Unlike most auctions, the winner of an SEM auction isn’t necessarily whoever pays the most. Maximum bid per SERP is one element search engines consider when awarding these positions, but they also consider user experience, content quality and relevance, keyword rankings… and a whole host of other factors that are primarily impacted by your SEO.
The bottom line is that search engines like Google recognize they can’t simply sell out for the highest bidder; they need to deliver a good and meaningful experience to searchers.
By incorporating SEO on the landing pages you’re promoting with your SEM initiatives, therefore, you can win auctions more frequently without necessarily having to pay more to do it. The more relevant, appealing, and search-optimized your content, the more bids you’ll win for your budget and the more effective your SEM campaign will be.
Ideally your SEO strategy will start driving enough qualified traffic over time for important keywords that you can scale back or even stop running paid campaigns for them.
SEM remarketing to SEO visitors
One of the most effective forms of SEM is retargeting ads. These ads automatically follow up with users who provided you with their contact information or previously interacted with your marketing or website.
The more effective your SEO, the more visitors your website will receive, and the more relevant those visitors will be. This will help you create a robust list of users you can retarget with SEM.
SEM for research, SEO for implementation
Because SEM campaigns generate so much engagement so quickly, they’re also a great way to learn about what your audience wants.
By A/B testing multiple SEM campaigns with small changes, for example, you can see what kind of promotions and messaging perform, and which don’t. Use this information to inform your larger SEO and content strategies.
Of course, this can also work the other way. If you experience exceptional organic success with a page or piece of content, try to figure out what made that content resonate with your audience. Apply what you learn into your next SEM campaign for better PPC rates.
By integrating and coordinating SEM and SEO campaigns this way, you will continue to generate highly useful information about how to market to your audience more effectively.
Learn more about elevating your brand’s rankings and authority in search.
The post How SEO and SEM Strategies Work Together appeared first on TopRank® Marketing.
Source:: toprankblog.com